
Teaching my studio about agentic AI.
I took an internal Harmonic synthesis I was already running and put the same data through a chatbot and an agent back to back, to show my colleagues the difference between asking an AI to help and asking it to do the work.
- Client
- Harmonic Design (internal)
- Year
- 2026
- Role
- Service Designer & analysis lead (with a colleague on the upstream synthesis)
The synthesis was the work. The experiment was what I wanted my colleagues to see.
Harmonic Design, the firm I work at, runs retros at the end of every engagement. The stickies get written, people say the right things in the room, and then the next project starts and the same problems show up again. The retros are not the problem; the gap between retro and change is. A colleague and I had been working that gap for months.
We combed through the Miro boards from across our project history (excluding one client engagement that needed to stay walled off), pulled in transcripts where we had them, and interviewed people about what specific stickies meant when the language was ambiguous. We grouped what we found into 40 themes across 9 categories of work. Then, in one of our studio Spotlights, we asked the whole team to rate every theme on two scales: severity (1–4, “not a big deal” through “must solve immediately”) and frequency (1–7, “every few years” through “daily”), with a “does not apply” option so people weren’t forced to invent a number for a kind of pain they’d never encountered.
That much was conventional service design synthesis: surfacing, clustering, getting the team to weigh in. What I did next is what this case is about.
Same data, two AI surfaces, back to back.
Twenty-five people times forty themes times two scales is 2,000 possible cells. We got 821 actual ratings back, with the rest being “does not apply” or themes a particular role never reached. That’s a real dataset, uneven across roles and with missingness that means something. It deserved real statistical handling.
I am not a statistician. I went to business school, and I still have to google the instructions on the rare occasions I want to make a pivot table. The version of me from a month ago would have built one anyway, eyeballed the top of the list, and called it a workshop input.
I wanted to do something different, and I wanted it to be useful to my colleagues, not just to me. So I took the same data and ran it through two AI surfaces back to back: first a regular chat window with my Sheet open beside it, then an agent that could see my files and run code. Same data, same goal, completely different working relationship. (I rebuilt the dataset as synthetic numbers first, so I could use my private Claude Code account without exposing internal Harmonic data. The themes and ratings shown anywhere downstream are not the real ones.)
Round one: chatbot as helpdesk over my shoulder.
I started the way most people I know start. A chat tab open, my spreadsheet open, and me copy-pasting back and forth, screenshotting charts, asking what was wrong with them. Within a couple of hours I had a bubble chart, two heatmaps, a filtered list of the seven critical themes, a pattern analysis grouping those seven into three underlying causes, and a markdown outline for a ten-slide deck. Useful. Entirely produced by my keystrokes.
The opening exchange looked like this — friendly, structured, and entirely about handing me a plan I would still have to execute.
A few moments from that round are worth naming, because they show what this mode is actually like.
- The bubble chart was wrong, and I had to fix it by hand. Sheets was reading the vote-count column as a separate data series instead of as the size dimension. The chatbot talked me through the menu changes; I clicked them. It said “go to Customize → Series → set Size to Vote Count.” I did. It worked. Useful, slow.
- A bubble was hidden behind another bubble, and nothing the chatbot suggested could fix it. Reorder source rows. Reorder series. Reduce opacity. Rebuild in Figma. None of it brought CR2 back into view. The chatbot couldn’t reach into my chart. I moved on without ever fully fixing it.
- The chatbot started building a story I had to stop. Halfway through, it had a heatmap based on count of mentions and was framing it around Leads “absorbing all the pain.” I stopped and asked why we were showing count instead of average. Count was going to be biased by who participated more, and I didn’t want a participation artifact dressed up as a finding. The chatbot agreed, we rebuilt with averages, and the “Leads absorb everything” pattern dissolved on contact. That catch wasn’t AI. That catch was my own critical reasoning.
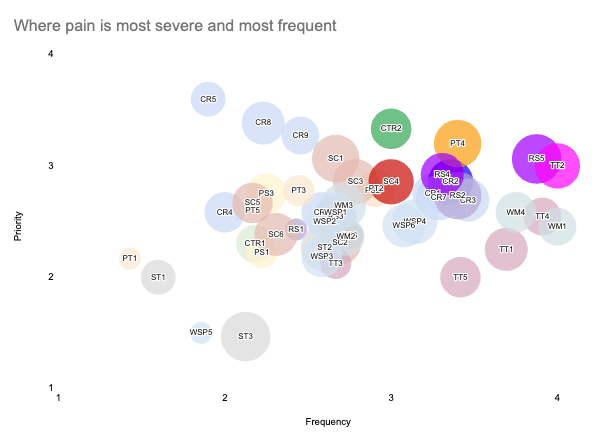
What I came out with at the end of round one: a crummy bubble chart that wasn’t really telling a story, two heatmaps in a Google Sheet, and a text document outlining what a ten-slide deck might look like. It felt like having a patient helpdesk person on the other end of a chat window who could answer any question about Sheets but who couldn’t actually open Sheets.
Round two: an agent inside my environment.
For round two I used Claude Code from my terminal, with access to my filesystem, my repos, and a deploy target. Same CSV, same goal.
The first thing I noticed was that I stopped describing the charts and software steps I wanted, and started describing what I wanted to learn.
Audience is leadership. Use whatever charts and structure best answer those questions. End with discussion questions, not conclusions. Don’t fabricate data. Show me what you compute and where it comes from. When you pick a visualization, briefly explain why you chose it.
The last sentence was the one that mattered. Asking the model to justify each visualization gave me something to push back against. It also gave me a running tutorial on what shape of chart fits what shape of question, which I’m now better at than I was before this project.
The agent read the CSV directly, computed the aggregations in Python, picked its own visualizations, and built a single-page interactive HTML site with everything embedded. In the same session it also produced a PDF, deployed the live site to a public URL on a hosting service I have an account with, and copied both files to a synced folder on my laptop.
I never opened a spreadsheet. I never wrote a formula. I have still never opened a Python file. I do not know what Python is.
The opening exchange in round two looked like this — directives, not menu walkthroughs.
Then I iterated. Some prompts that show what this mode actually felt like:
- “The role-average bars aren’t telling me anything useful. Show me what categories each role rated highest, and whether those overlap.” It rebuilt the section as a category-by-role grid with each role’s top three marked. That grid was an answer to a question I hadn’t quite articulated.
- “Add a section showing every theme rated severe, even the rare ones, so we can talk about the ‘severe but infrequent’ kind of fix separately from the everyday ones.” Done, with each theme badged appropriately.
- “The frequency scale is bucketed labels, not a continuous line. An average of 3.5 doesn’t mean ‘daily friction,’ it means ‘between most projects and once per project.’ Make the prose reflect that.” Re-anchored the language across the whole site in one pass.
- “Don’t use theme codes in the narrative copy, spell them out in plain language.” Done across nine sections in seconds. In round one, that single edit would have been an afternoon of opening Slides and rewriting nine slides by hand.
What’s actually different
Having done both back to back, here is the way I would put it now.
A chatbot helps you think. An agent helps you get work done. Same model underneath, in some cases. Completely different relationship. The chatbot is a colleague at the other end of a chat window: smart, patient, and able to run real code on data you give it. But everything they produce lives in their window, not in yours. You are the bridge between their output and your work. With the agent, that bridge collapses. They share your environment. They both think and do.
The bottleneck shifts from execution to articulation. In round one, the limit was how well I could drive Sheets and how cleanly I could move output into a deliverable. In round two, the limit was how clearly I could describe what I wanted. That is a different muscle, and it is closer to the muscle service designers already have. Briefing. Critiquing. Naming what’s missing. Pushing back when something doesn’t sit right.
You stop pre-deciding the artifact. In round one I had to know I wanted a bubble chart, a heatmap, a bar chart. In round two I gave the agent questions and let it pick. Some of what came back was better than what I would have asked for. The category-by-role grid in particular was an answer to a question I had not quite articulated.
Iteration becomes cheap. “Restructure that section, change the framing, anchor the language to bucket labels, soften the tone” is a single prompt with the agent. It is an afternoon with the chatbot. That changes what you are willing to revise.
I did not write the HTML. I wrote the brief, made the synthesis judgments, sharpened the language, and decided what to cut. The model did the analysis, the visualization choices, and the layout. That division of labor is the point.
Three pushes that changed the deliverable.
Three places I pushed back hardest:
- Push on grouping. The model proposed four clusters of themes. One of them (“lead capacity”) didn’t fit with the others, and the takeaway language papered over that fact. I asked it to either justify the cluster or treat the outlier honestly. It chose honesty: the final deck has three patterns plus one “stubborn outlier” called out as a structural decision rather than a process to redesign.
- Push on borderline cases. The first cut of “critical themes” was too tidy: it implied a cleaner threshold than the data supported. I asked the agent to look again at the items just outside the cutoff. It surfaced a theme (“methodology baked in by sales before assessment”) with the dataset’s highest severity score that had landed just under the frequency threshold. That theme became its own callout in the final deliverable, and one of the open questions for leadership at the end.
- Push on tone. A pass through the recommendations section came back too prescriptive: too many “we will” statements aimed at a leadership audience that hadn’t been in the room for the analysis. I asked the agent to convert the strongest claims into questions for discussion, and to preserve only the recommendations that the data actually supported. The final section is named “Open questions for leadership,” not “Recommended next steps.”
What the final piece looks like
The output is an interactive HTML site titled Service designers look at their own journey, deployed to a public URL the studio can open in a meeting. It is structured the way a leadership presentation should be: the landscape first (all 40 themes plotted), then the critical few (filtered to severe and frequent), then patterns (the clusters that read as the same underlying problem), then cuts by seniority and by category, then what we’re explicitly not chasing, then a recommendations section honestly named as three streams plus one structural decision, and finally open questions for leadership rather than a hard close.
It is in Harmonic’s brand colors and typefaces, with hoverable bubbles, sortable lists, and visual signals (the “Fix Now” zone is shaded; outliers are flagged in their own cards). The site opens with a panel that explains the rating scales and what blanks mean, because half of leadership wasn’t in the room when the scales were set. A persistent banner at the top names the data as synthetic, so no one mistakes the example for the underlying engagement.
Scroll to explore the live deliverable
What I’m taking from this
A few things I want to do differently the next time I run this kind of synthesis with a working analyst in the loop:
- Brief the questions, not the chart types. Every time I specified a visualization upfront, I got a worse output than when I described what I wanted to learn and let the model pick. The chart shapes I’d never reached for, like a category × role heatmap, outperformed the ones I would have defaulted to.
- Verify the math when something surprises you. When the model said something I didn’t expect, I asked to see the calculation. Twice it caught its own arithmetic; once I caught a pattern that was real but more nuanced than the takeaway implied.
- Stop when it tells the story, not when it’s perfect. I could have iterated on the deck for another week. The marginal return after round six was very small. The version we presented was the one where leadership could read it once and have an opinion.
What I’m still thinking about
The retro process at Harmonic was not broken. The synthesis-to-action gap was. This deliverable is one half of closing that gap; whether anything actually changes depends on what leadership does with the open questions at the end. I’ll know in a quarter or two whether the streams of work named in the recommendations get owned by anyone, or whether the deck joins the stack of well-made artifacts that don’t move the studio.
The other thing I’m still thinking about: how much of what I just did is portable. The same rough pattern (a tagged synthesis deliverable feeding an agentic-AI analyst that produces an interactive output) could shorten the back half of a research engagement substantially. The constraints on client work are different (data sensitivity, NDA, audience appetite for “an AI made the charts”), but the underlying move scales. And inside Harmonic, the move I most want my colleagues to make is the one from round one to round two: stop ferrying things back and forth between a chat tab and your work, and let the agent share the environment with you. The gap between “I have read about agents” and “I am using them in my actual work” is much smaller than it looks. The thing that gets you across is not technical skill. It is a willingness to describe what good looks like, in your own words, and to keep pushing until you get there.